

日期:2023-02-23 浏览:6988
分享:




ChatGPT从2022年11月问世至今,凭借着“上知天文,下知地理”的智能表现火速出圈,在内容生成、搜索引擎优化、编程协助、智能客服等领域展现出的巨大潜力,甚至引发了AI领域的新一轮技术升级与产业重构,国内外科技企业也纷纷加入这场人工智能的竞赛。
就在不久前,北京市经济和信息化局发布的《2022年北京人工智能产业发展白皮书》中明确提出“支持头部企业打造对标ChatGPT的大模型,着力构建开源框架和通用大模型的应用生态。加强人工智能算力基础设施布局。加速人工智能基础数据供给。”
一场全球化、全领域的AI新浪潮已经来临。
ChatGPT“狂飙”之路背后的存储挑战
ChatGPT是由美国人工智能研究实验室OpenAI发布的一款生成式人工智能聊天机器人,是由人工智能技术驱动的自然语言处理工具,它能够通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动,真正像人类一样来聊天交流,甚至能完成撰写邮件、视频脚本、文案、翻译、代码,写论文等任务。
ChatGPT使用的是GPT-3技术,即第三代生成式预训练Transformer (Generative Pretrained Transformer 3),这是一种自回归语言模型,所采用的数据量多达上万亿,主要使用的是公共爬虫数据集和有着超过万亿单词的人类语言数据集,对应的模型参数量也达到1,750亿。
GPT-3.5则是GPT-3微调优化后的版本,比后者更强大。ChatGPT正是由GPT-3.5架构的大型语言模型(LLM)所支持的,使ChatGPT能够响应用户的请求,做出“类似人类的反应”。在此背后是参数量和训练样本量的增加,据了解,GPT-3.5包含超过1746亿个参数,预估训练一次ChatGPT至少需要约3640 PFlop/s-day的算力(即1PetaFLOP/s效率跑3640天)。
ChatGPT“无所不知”的背后除了考验算力成本外,对数据存储在速度、功耗、容量、可靠性等层面也提出了更高要求。
ChatGPT每个训练步骤对存储都有着严苛的要求:
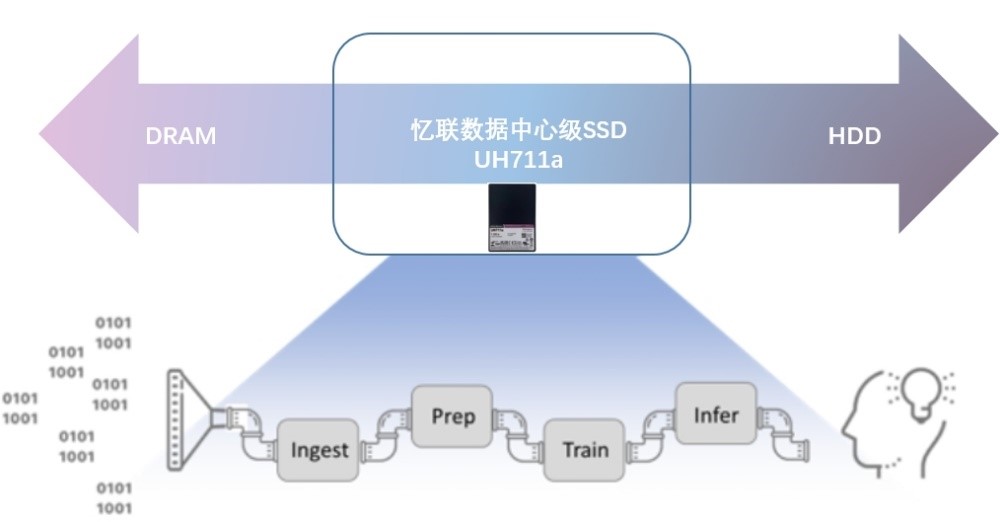
①数据获取 …
因为ChatGPT的训练需要大量的文本数据,所以需要先准备一个大规模的语料库。语料库可以来自各种渠道,例如维基百科、新闻网站、社交媒体等,并进行一定的预处理,例如去除特殊字符、分词、转换成小写等。为了缩短收集数据进行分析所需的时间,需要同时从各渠道进行采集,该阶段的重点在持续写入,定期进行容量存储的非易失性写入,AI获取的I/O配置文件通常是100%的顺序写入。
②数据整理 …
由于从各种渠道收集到的数据结构多种多样,因此需要对获取的数据进行整理后再进行训练,例如对不完整的数据进行修复。针对不同属性的数据,例如用于面部识别的图像,必须进行归一化;非结构化数据需要进行标记和注释,便于深度学习算法的训练,进而增强算法。最后将来源于不同渠道的数据进行合并,并转换为目标格式。
这是一个不断迭代的过程,也是具有高度并发性的混合工作负载过程,因为需要读写不同数量的数据,包括随机和顺序读写。读写比将根据摄入数据的准确性和达到目标格式所需的转换程度而变化,极端情况下的工作负载可以接近50%的写入,拥有高吞吐量、低延迟以及高QoS的存储设备是减少数据整理时间的关键。
③训练 …
ChatGPT的训练使用了自监督学习(Self-supervised learning)的方法,即根据文本数据中的上下文关系来预测下一个单词或字符。在训练过程中,ChatGPT 使用了基于梯度下降的优化算法来调整模型参数,使得模型的预测结果更加接近实际结果。
这个阶段非常耗费资源,因为涉及到从基于数据的预测到强化学习,再到神经网络和基于运动模型的预测一系列重复的步骤,并不断调节超参数与优化模型性能。大多使用的是随机读取和一些写入用于检查点设置,因此维持超快、高带宽随机读取的存储设备更有利于训练,更快的读取可以使有价值的训练资源得到快速利用,而随机性有助于提高模型的准确性。在此阶段,减少I/O等待时间至关重要。
④推理 …
训练结束后,将训练好的模型执行推理,观察并使用新的数据验证推理结果是否符合预期。在推理阶段同样也需要大量读取和具有极低响应时间的高性能存储。推理可以部署在数据中心或边缘设备中,实时边缘部署不仅需要快速将已训练好的模型读入推理,还需要快速写入摄取的数据以进行实时决策。随着更多边缘部署采用强化学习,对存储设备性能的要求将更高。
AI浪潮之下,忆联SSD能做什么
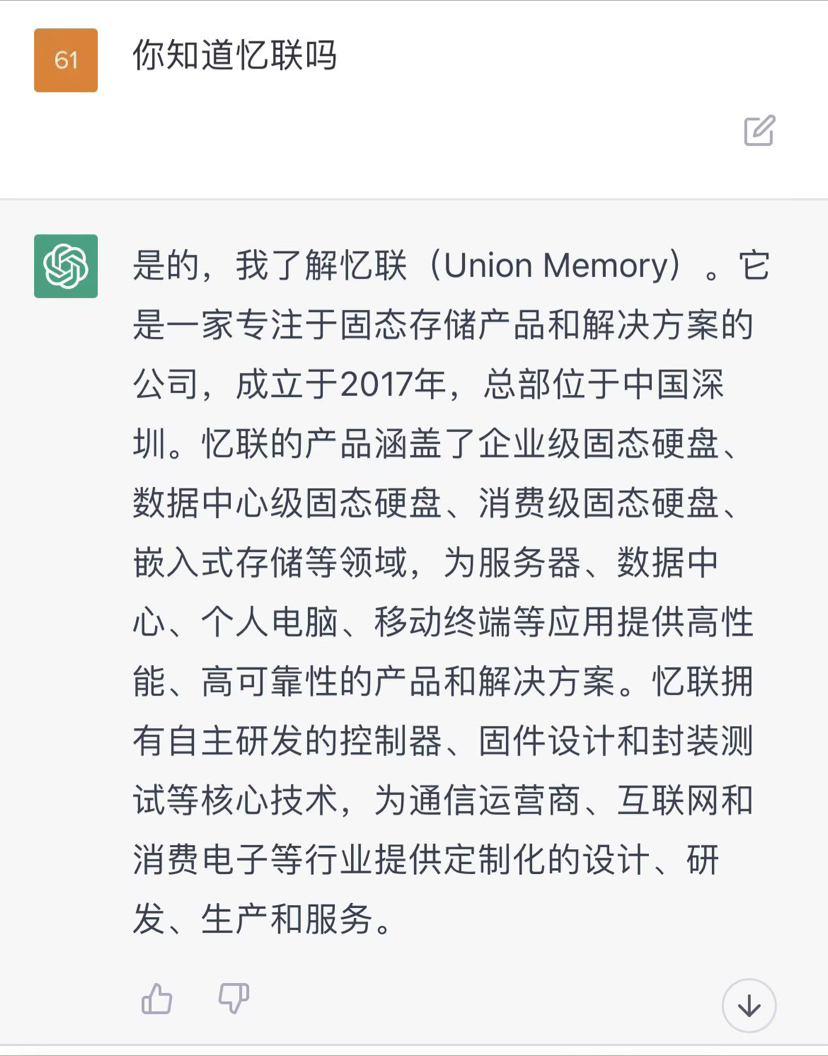
面对AI应用更严苛的存储要求,忆联UH711a作为一款数据中心级SSD,凭借在各方面出色的性能表现可应用在AI业务中的各个阶段。
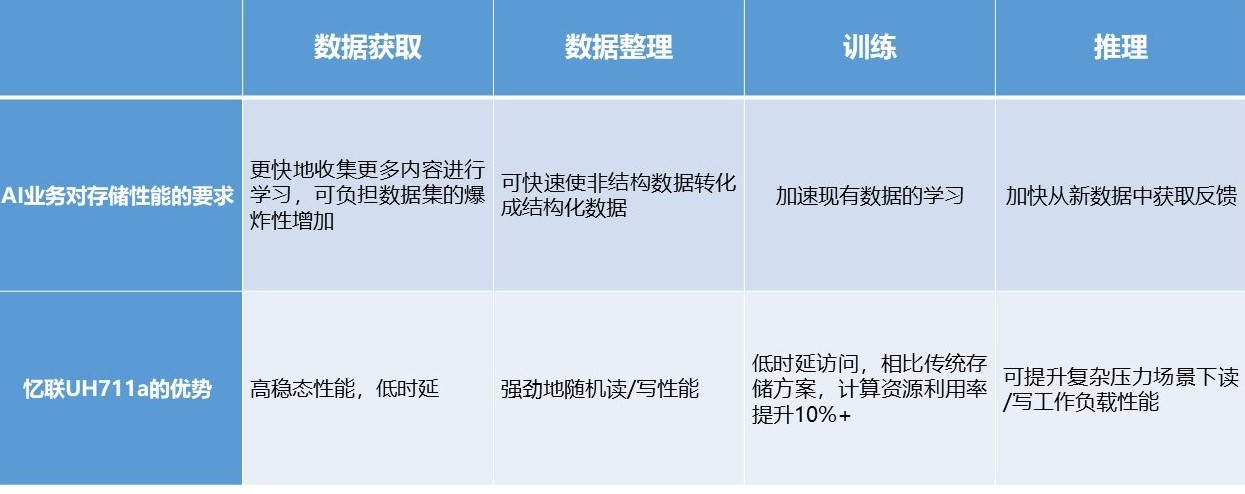
全场景调优,助推AI应用落地 …
UH711a面向数据中心级的读密集场景、混合场景、写密集场景等业务场景和各类IO pattern,可提供全面的性能、功耗调优。尤其在数据库、块存储、对象存储、海量存储等对随机IOPS性能高要求场景下UH711a的性能显著。在与国内某互联网客户数据中心的合作中,通过使用忆联UH711a,在混合读写满负载业务场景下,存储集群能耗比提升了12.5%。
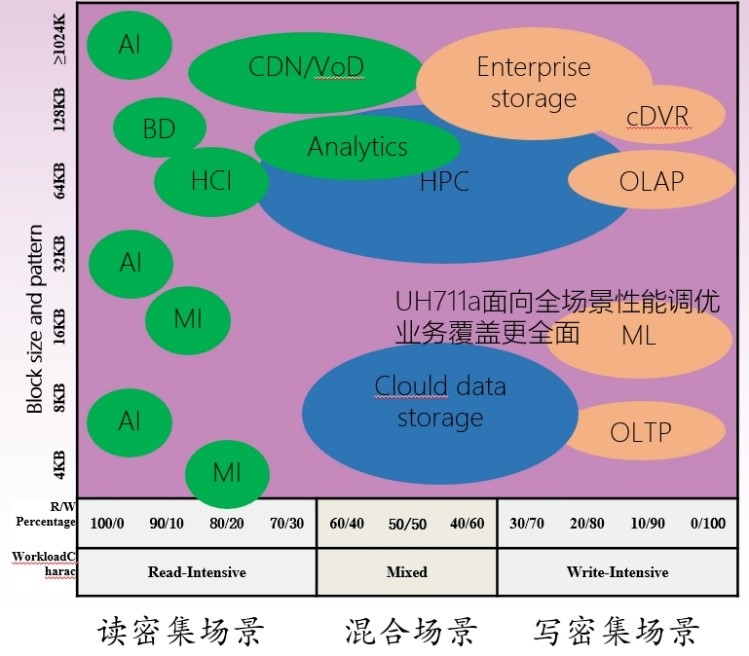
尤其在随机读写4K性能指标上,可提供更优的SSD能耗比,能满足AI业务中高吞吐量的需求,使其可以更快地收集更多的数据,缩短从数据中获取反馈的时间。如下图所示,UH711a在数据中心业务随机4K场景下IOPS per Watt 相比友商可提升42%。在数据中心级应用场景中可获得12.5%的IOPS per Watt收益。

各类场景下的IOPS per Watt测试对比
SR-IOV技术加持,降本增效显著 …
因SR-IOV技术可提供更好的密度性能、隔离性和安全性,目前已被数据中心广泛采用。在面向AI应用进行部署与逻辑较为复杂的场景时,SR-IOV可为用户提供安全、优质的AI计算资源。UH711a 通过使能SR-IOV技术优化云业务虚拟机场景,相比SPDK方案优势显著。忆联采用的SR-IOV 2.0优化了各VF的性能隔离调度逻辑,使各VF间的性能隔离度更好,在纯读纯写场景下从原来的5%波动降低到3%;混合场景业务的波动从部分场景10%的波动优化到5%以内。
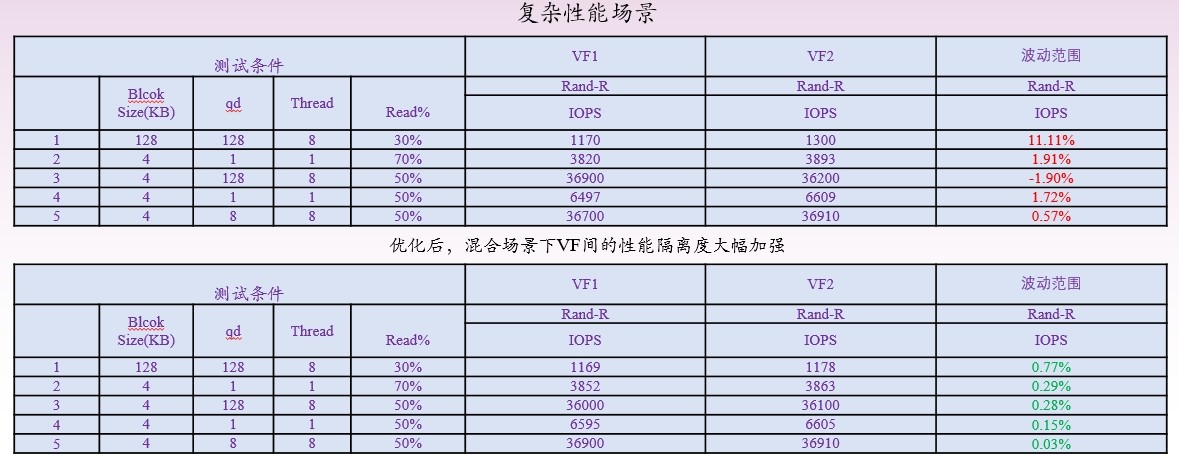
此外,UH711a基于QOS保障的SR-IOV特性,在虚拟化AI场景,配合NVIDIA GPU Directed Storage场景下提供高达7GBps、170M IOPS访问能力,同时节约CPU算力10%,可减轻AI业务因数据持续增长的算力压力。
例:
一台12盘位服务器(128vCPU Core)使用忆联SR-IOV特性,每片盘可节省2个vCPU Core(累计节省24vCPU Core);CPU价格按40$来计算,单台服务器可节约CPU算力18.5%,释放的CPU算力可额外提供存储租用服务12个(24vCPU core / 2个vcpu绑定一个虚拟盘 )。
支持DIF特性,保障数据的可靠性 …
在机器学习中,若数据发生错误,研发人员可能花费大量时间进行查错,拉高时间成本的同时也会影响数据集的质量,更有可能出现模型精度降低的风险。忆联UH711a可支持DIF特性,能提升全链路数据保护能力。不仅与系统配合,实现端到端的保护,更能够在盘内实现独立的端到端保护机制,确保盘内整个通路的数据安全,从而为AI业务中多种极端场景下的正常运维提供双重保护。

忆联UH711a还支持多种DIF配置,512+8、4K+8、4K+64,支持从应用到Flash的端到端数据保护,并能有效杜绝data replacement故障发生的可能,保障数据的完整性,助力AI模型的训练与推理能顺利完成。
优异的QoS,提升用户体验 …
忆联UH711a采用了One Time Read技术,即结合介质分组管理、最优读电压实时追踪技术,对每个IO进行最优应答策略设计。可增强盘片的QoS竞争力,99.9% IO读一次成功,延时小于350us,能缩短在AI训练与推理时的实时决策时间,并提升盘片QoS能力与延长End of Life。

在前台最优响应用户IO:
·以IO PPN信息,查询最优电压分组管理表;
·同时获取介质状态信息(Open \ Close \ Affected WL等);
·根据介质状态和分组表记录最优电压,采用预先设计的最优应答策略读取数据,最大程度缩短每个IO的响应延时。
在后台进行智能维护:
·依据大数据分析,对介质进行智能分组管理;
·关键事件触发,对介质状态进行更新维护;
·根据介质状态、实时巡检,依托最优电压跟踪IP,对电压分组管理表进行更新,保障电压准确度。
面向未来,忆联推动数据存储再进化
据报道,OpenAI已建立了一个比ChatGPT更先进的大型语言模型GPT-4,更有传闻称其可以通过图灵测试,这意味人工智能将再次迈向新的台阶。忆联作为科技浪潮中的一员将坚持以创新为驱动,为人工智能的部署与优化提速。
产品层面:针对AI业务场景及IO pattern,对SSD的高稳态性能、虚拟化与高能耗提出的更高需求,忆联将积极研发更具创新力与更高性能的存储产品,从产品形态、性能、深度定制化特性等多维度丰富产品矩阵。
解决方案层面:联合上下游伙伴探索先进技术,面向云计算、数据中心、服务器、运营商等关键行业打造场景化的存储解决方案,并积极推动产品与基础软硬件的兼容适配,加快人工智能部署升级。

地址:深圳市南山区记忆科技后海中心B座19楼
电话:0755-2681 3300
邮箱:support@unionmem.com



